Building reliable mobile applications
14 Aug 2020This post was originally published on Shopify’s Engineering Blog. I’m re-posting it here for posterity.

Merchants worldwide rely on Shopify’s Point Of Sale (POS) app to operate their brick and mortar stores. Unlike many mobile apps, the POS app is mission-critical. Any downtime leads to long lineups, unhappy customers, and lost sales. The POS app must be exceptionally reliable, and any outages resolved quickly.
Reliability engineering is a well-solved problem on the server-side. Back-end teams are able to push changes to production several times a day. So, when there’s an outage, they can deploy fixes right away.
This isn’t possible in the case of mobile apps as app developers don’t own distribution. Any update to an app has to be submitted to Apple or Google for review. It’s available to users for download only when they approve it. A review can take anywhere between a few hours to several days. Additionally, merchants may not install the update for weeks or even months.
It’s important to reduce the likelihood of bugs as much as possible and resolve issues in production as quickly as possible. In the following sections, we will detail the work we’ve done in both these areas over the last few years.
Testing
We rely heavily on automation testing at Shopify. Every feature in the POS app has unit, integration, functional, and UI snapshot tests. Developers on the team write these simultaneously as they are adding new functionality to the code-base. Changes aren’t merged unless they include automated tests that cover them. These tests run for each push to the repo in our Continuous Integration environment. You can learn more about our testing strategy here.
Besides automation testing, we also perform manual testing at various stages of development. Features like pairing a Bluetooth card reader or printing a receipt are difficult to test using automation. While we use mocks and stubs to test parts of such features, we manually test the full functionality.
Sometimes tests that can be automated, inadvertently end up in the manual test suite. This causes us to spend time testing something manually when computers can do that for us. To avoid this, we audit the manual test suite every few months to weed out all such test cases.
Code Reviews
Changes made to the code-base aren’t merged until reviewed by other engineers on the team. These reviews allow us to spot and fix issues early in the life-cycle. This process works only if the reviewers are knowledgeable about that particular part of the code-base. As the team grew, finding the right people to do reviews became difficult.
To overcome this, we have divided the code-base into components. Each team owns the component(s) that make up the feature that they are responsible for. Anyone can make changes to a component, but the team that owns it must review them before merging. We have set up Code Owners so that the right team gets added as reviewers automatically.
Reviewers must test changes manually, or in Shopify speak, “tophat”, before they approve them. This can be a very time-consuming process. They need to save their work, pull the changes, build them locally, and then deploy to a device or simulator. We have automated this process, so any Pull Request can be top-hatted by executing a single command:
dev android tophat <pull-request-url>
dev ios tophat <pull-request-url>
You can learn more about mobile tophatting at Shopify here.
Release Management
Historically, updates to POS were shipped whenever the team was “ready.” When the team decided it was time to ship, a release candidate was created, and we spent a few hours testing it manually before pushing it to the app stores.
These ad-hoc releases made sense when only a handful of engineers were working on the app. As the team grew, our release process started to break down. We decided to adopt the release train model and started shipping monthly.
This method worked for a few months, but the team grew so fast that it wasn’t working anymore. During this time, we went from being a single engineering team to a large team of teams. Each of these teams is responsible for a particular area of the product. We started shipping large changes every month, so testing release candidates was taking several days.
In 2018, we decided to switch to weekly releases. At first, this seemed counter-intuitive as we were doing the work to ship updates more often. In practice, it provided several benefits:
- The number of changes that we had to test manually reduced significantly.
- Teams weren’t as stressed about missing a release train as the next train left in a few days.
- Non-critical bug fixes could be shipped in a few days instead of a month.
We then made it easier for the team to ship updates every week by introducing Release Captain and ShipIt Mobile.
Release Captain
Initially, the engineering lead(s) were responsible for shipping updates, which included:
- making sure all the changes are merged before the cut-off
- incrementing the build and version numbers
- updating the release notes
- making sure the translations are complete
- creating release candidates for manual testing
- triaging bugs found during testing and getting them fixed
- submitting the builds to app stores
- updating the app store listings
- monitoring the rollout for any major bugs or crashes
As you can see, this is quite involved and can take a lot of time if done by the same person every week. Luckily, we had quite a large team, so we decided to make this a rotating responsibility.
Each week, the engineer responsible for the release is called the Release Captain. They work on shipping the release so that the rest of the team can focus on testing, fixing bugs, or working on future releases.
Each engineer on the team is the Release Captain for two weeks before the next engineer in the schedule takes over. We leverage PagerDuty to coordinate this, and it makes it very easy for everyone to know when they will be Release Captain next. It also simplifies planning around vacations, team offsites, etc.
To simplify things even further, we configured our friendly chatbot, spy, to automatically announce when a new Release Captain shift begins.


ShipIt Mobile
We’ve automated most of the manual work involved in doing releases using ShipIt Mobile. With just a few clicks, the Release Captain can generate a new release candidate.
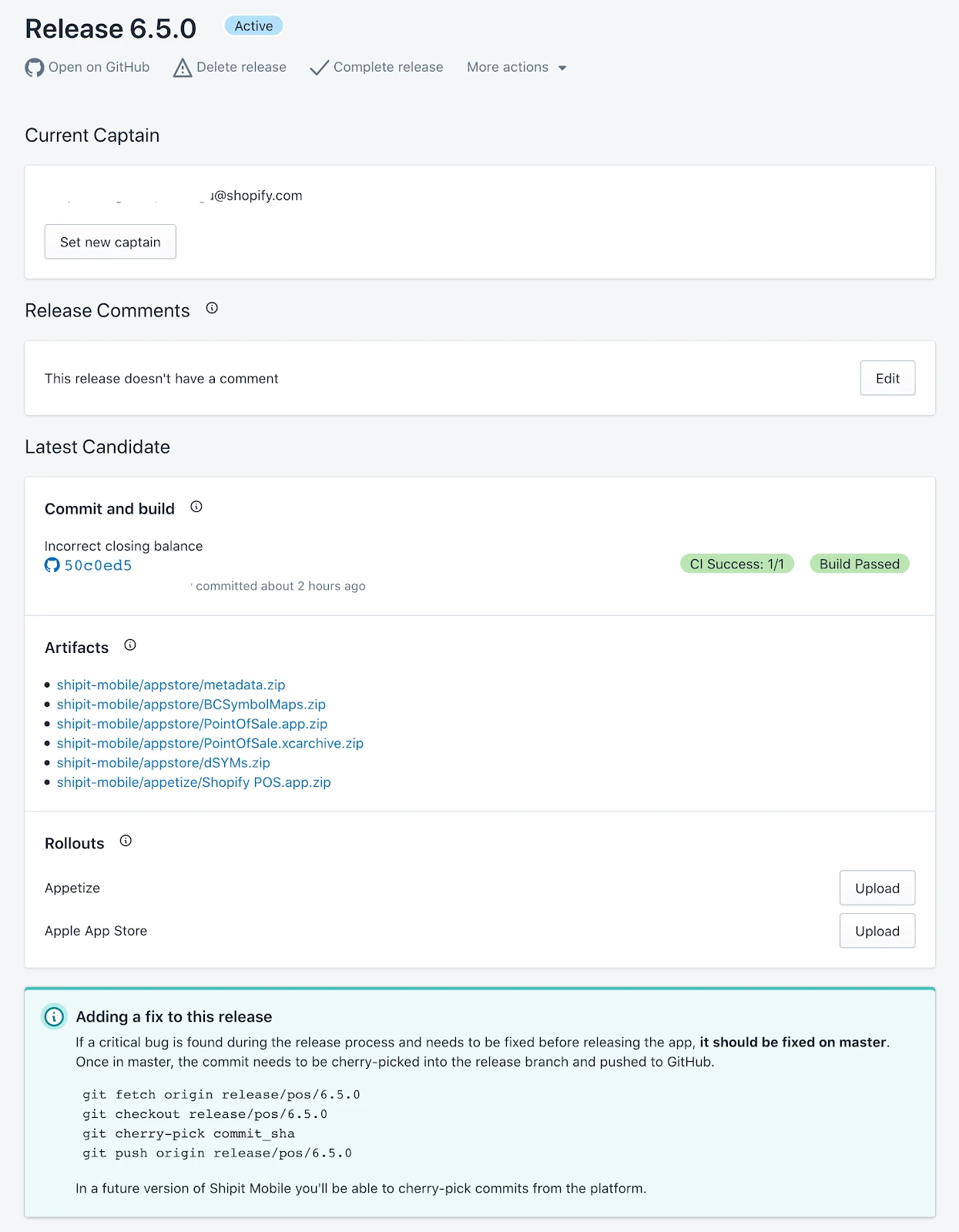
Once ready, the rest of the team is automatically notified in Slack to start testing.

After fixing all the bugs found, the update is submitted to the app store with just a single click. You can learn more about ShipIt Mobile here. These improvements not only make weekly releases easier, but they also make it significantly faster to ship hotfixes in case of a critical issue in production.
Staged Rollouts
Despite our best efforts, bugs sometimes slip into production. To reduce the surface area of a disruption, we make the updates available only to a small fraction of our user base at first. We then monitor the release to make sure there are no crashes or regressions. If everything goes well, we gradually increase the percentage of users the update is available to over the next few days. This is done using Phased Releases and Staged Rollouts in iOS AppStore and Google Play, respectively.
The only exception to this approach is when a fix for a critical issue needs to go out immediately. In such cases, we make the update available to 100% of the users right away. We also can block users from using the app until they update to the latest version.
We do this by having the POS app query the server for the minimum supported version that we set. If the current version is older than that, the app blocks the UI and provides update instructions. This is quite disruptive and can be annoying to merchants who are trying to make a sale. So we do it very rarely and only for critical security issues.
Beta Flags
Staged rollouts are useful for limiting how many users get the latest changes. But, they don’t provide a way to explicitly pick which users. When building new features, we often handpick a few merchants to take part in early-access. During this phase, they get to try the new features and give us feedback that we can work on before a final release.
To do that, we put features, and even big refactors behind server-side beta flags. Only merchants whose stores we have explicitly set a beta flag will see the app’s new feature. This makes it easy to run closed betas with selected merchants. We also can do staged rollouts for beta flags, which gives us another layer of flexibility.
Automated Monitoring and Alerts
When something goes wrong in production, we want to be the first to know about it. The POS app and backend is instrumented with comprehensive metrics, reported in real-time. Using these metrics, we have dashboards set up to track the health of the product in production.
Using these dashboards, we can check the health of any feature in a geography with just a few clicks. For example, the % of successful chip transactions made using a VISA credit card with the Tap, Chip & Swipe reader in the UK, or the % of successful tap transactions made using an Interac debit card with the Tap & Chip reader in Canada for a particular merchant.
While this is handy, we didn’t want to have to keep checking these dashboards for anomalies all the time. Instead, we wanted to get notified when something goes wrong. This is important because while most of our engineering team is in North America, Shopify POS is used worldwide.
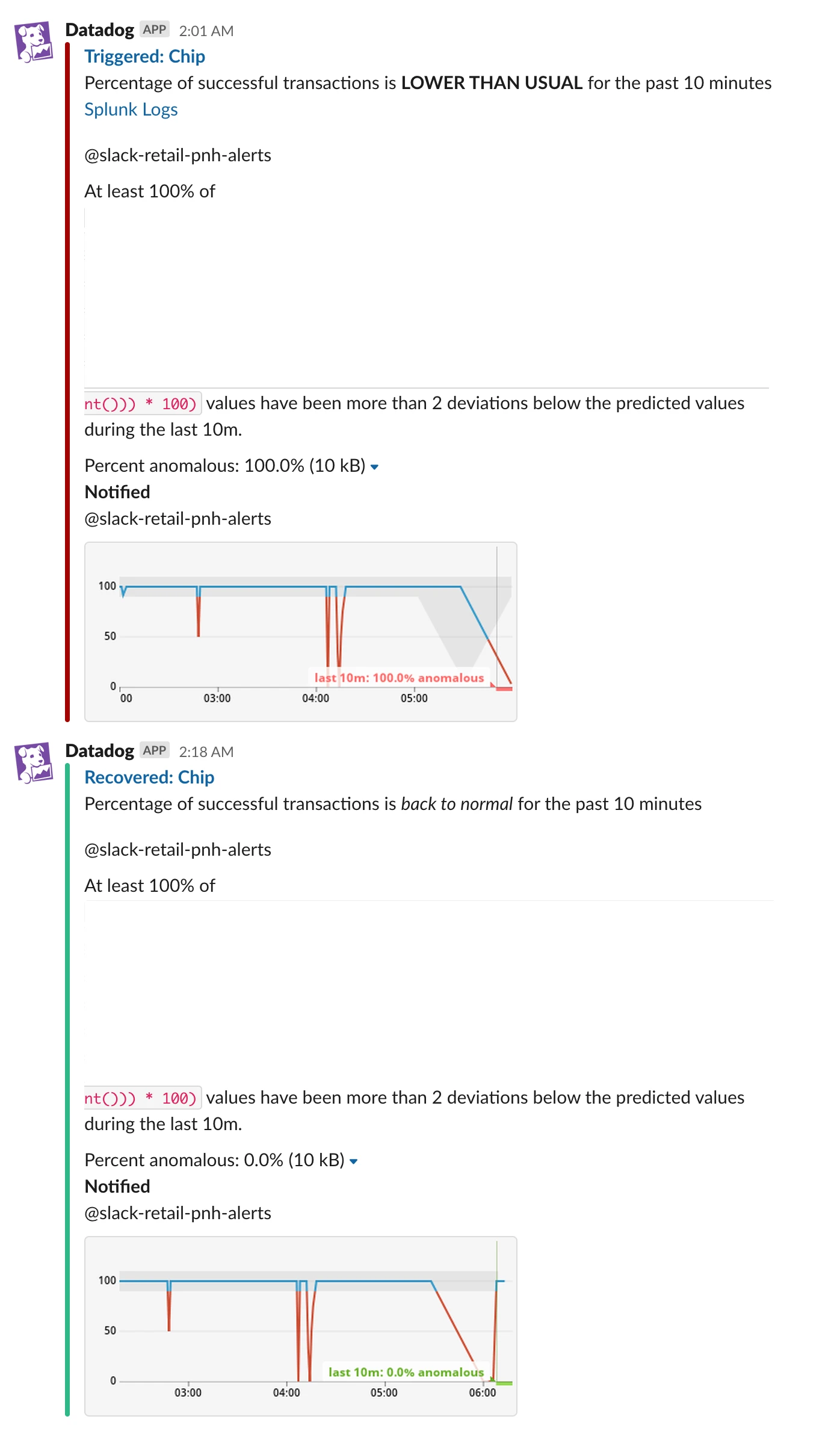
This is harder to do than it may seem because the volume of commerce varies throughout the year. Time of day, day of the week, holidays, seasons, and even the ongoing pandemic affect how much merchants are able to sell. Setting manual thresholds to detect issues can cause a lot of false negatives and alert fatigue. To overcome this, we leverage Datadog’s Anomaly Detection. Once the selected algorithm has enough data to establish a baseline, alerts will only get fired if there’s an anomaly for that particular time of the year.
We direct these alerts to Slack so that the right folks can investigate and fix them.
Handling Outages
Air Traffic Control
In the early days of POS, bugs and outages were reported in the team Slack channel, and whoever on the team had the bandwidth, investigated them. This worked well when we had a handful of developers, but this approach didn’t scale as the team grew. Issues kept going to just a few folks who had the most context, and teams kept getting distracted from regular project work, causing delays.
To fix this, we set up a rotating on-call schedule called Retail ATC (Air Traffic Control). Every week, there is a group of developers on the team dedicated to monitoring how things are working in production and handling outages. These developers are responsible only for this and are not expected to contribute to regular project work. When there are no outages, ATCs spend time tackling tech debt and helping our Technical Merchant Support team.
Every developer on the team is on-call for two weeks at a time. The first week they are Primary ATC, and the next week they are Secondary ATC. Primary ATC is paged when something goes wrong, and they are responsible for triaging and investigating it. If they need help or are unavailable (commute time, connectivity issues, etc.), the Secondary ATC is paged. ATCs are not expected to fix all issues that arise by themselves, while often they can. They are instead responsible for working with the team that has the most context.

Since we offer the POS app on both Android on iOS, we have ATC schedules for developers that work on each of those apps. Some areas, like payments, for instance, need a lot of domain knowledge to investigate issues. So we have dedicated ATCs for developers that work in those areas.
Having folks dedicated to handling issues in production frees up the rest of the team to focus on regular project work. This approach has greatly reduced the amount of context switching teams had to do. It has also reduced the stress that comes with the responsibility of working on a mission-critical mobile application.
Over the last couple of years, ATC has also become a great way for us to help new team members onboard faster. Investigating bugs and outages exposes them to various tools and parts of our codebase in a short amount of time. This allows them to become more self-sufficient quickly. However, being on-call can be stressful. So, we only add them to the schedule after they have been on the team for a few months and have undergone training. We also pair them with more experienced folks when they go on call.
Incident Management
When an outage occurs, it must be resolved as quickly as possible. To do this, we have a set of best practices that the team can follow so that we can spend more time investigating the issue vs figuring out how to do something.
An incident is started by the ATC in response to an automated alert. ATCs use our ChatOps tools to start the incident in a dedicated Slack channel.

Incidents are always started in the same channel, and all communication happens in it. This is to ensure that there is a single source of information for all stakeholders.
As the investigation goes on, findings are documented by adding the 📝 emoji to messages. Our chatbot, spy automatically adds them to a service disruption document and confirms it by adding a ✅ emoji to the same message.
Once we identify the cause of the outage and verify that it has been resolved, the incident is stopped.
The ATC then schedules a Root Cause Analysis (RCA) for the incident on the next working day. We have a no-blame culture, and the meeting is focused on determining what went wrong and how we can prevent it from happening in the future.
At the end of the RCA, action items are identified and assigned owners. Keeping track of outages over time allows us to find areas that need more engineering investment to improve reliability.
Thanks to these efforts, we’ve been able to take an app built for small stores and scale it for some of our largest merchants. Today, we support a large number of businesses to sell products worth billions of dollars each year. Along the way, we also scaled up our engineering team and can ship faster while improving reliability.
We are far from done, though, as each year we are onboarding bigger and bigger merchants onto our platform. If these kinds of challenges sound interesting to you, come work with us! Visit our Engineering career page to find out about our open positions. Join our remote team and work (almost) anywhere. Learn about how we’re hiring to design the future together - a future that is digital by default.